joRge benjoR
Jorge Benjor e sua Alquimia Musical, agora no R
Eu sou um grande fã de Jorge Benjor, gosto que herdei de meu pai. O suíngue, as batidas, as letras… Se o dia não está bom, basta ouvir “A Tábua de Esmeralda”, lançado em 1974, categorizado como “samba rock”, que tudo melhora. É, junto com “Racional vol. 1”, do Tim Maia, “Gita”, do Raul Seixas, e “Terra”, do Sá, Rodrix e Guarabyra, um dos meus discos favoritos.
Ao mesmo tempo, sou um entusiasta da ciência de dados. Embora cientista político de formação (e essa se mantém minha maior paixão), enxergo a ciência de dados como uma grande ferramenta para compreender o mundo, que me auxilia diariamente no meu fazer científico. Meu trabalho é todo realizado na linguagem R e no software RStudio.
Recentemente, descobri o pacote spotifyR, que utiliza a API (Application Programming Interface, ou interface de programação de aplicativos) do Spotify diretamente no R, podendo criar bancos e trabalhar com esses dados, analisando músicas, artistas, playlists, etc.
Resolvi então somar os dois gostos: Jorge Benjor e R através do SpotifyR e fazer uma rápida análise do artista, a partir dos dados disponibilizados pelo Spotify, a qual compartilho com vocês, leitores, aqui, em um formato de passo-a-passo.
A utilização do spotifyR pode ser vista aqui. Em resumo, é preciso criar uma conta de desenvolvedor no Spotify, para ter acesso à API, gerar um código secreto e um ID, e posteriormente um token. Maiores detalhes no link acima.
O primeiro passo, então, é carregar os pacotes que serão utilizados. No meu caso, optei pelo tidyverse, janitor, hrbrthemes, spotifyr, plotly e ggalt. Utilizo, para agilizar o processo, o pacman, que é um outro pacote, aqui carregado em lazy, que me permite abrir diversos pacotes de uma só vez. Vale a pena instalá-lo, pra quem não o conhece.
pacman::p_load(tidyverse, janitor, spotifyr, hrbrthemes, ggalt, plotly, knitr, kableExtra)Em seguida, baixei todos os dados referentes ao Jorge utilizando a função get_artist_audio_features(), e armazenei em um banco denominado jbj.
jbj <- get_artist_audio_features("jorge benjor")## Warning: `mutate_()` was deprecated in dplyr 0.7.0.
## Please use `mutate()` instead.
## See vignette('programming') for more helpDando uma olhada no que o banco nos oferece…
glimpse(jbj)## Rows: 751
## Columns: 39
## $ artist_name <chr> "Jorge Ben Jor", "Jorge Ben Jor", "Jorge …
## $ artist_id <chr> "5JYtpnUKxAzXfHEYpOeeit", "5JYtpnUKxAzXfH…
## $ album_id <chr> "0NdVGJ7e99By4k43k39nUY", "0NdVGJ7e99By4k…
## $ album_type <chr> "album", "album", "album", "album", "albu…
## $ album_images <list> [<data.frame[3 x 3]>, <data.frame[3 x 3]…
## $ album_release_date <chr> "2015-10-30", "2015-10-30", "2015-10-30",…
## $ album_release_year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015,…
## $ album_release_date_precision <chr> "day", "day", "day", "day", "day", "day",…
## $ danceability <dbl> 0.519, 0.560, 0.704, 0.482, 0.801, 0.429,…
## $ energy <dbl> 0.825, 0.662, 0.716, 0.400, 0.384, 0.699,…
## $ key <int> 1, 6, 9, 6, 3, 9, 4, 0, 7, 9, 11, 6, 0, 4…
## $ loudness <dbl> -9.326, -8.468, -7.726, -11.845, -11.551,…
## $ mode <int> 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0,…
## $ speechiness <dbl> 0.1140, 0.0494, 0.0734, 0.0310, 0.0419, 0…
## $ acousticness <dbl> 0.3250, 0.7060, 0.5310, 0.7690, 0.7260, 0…
## $ instrumentalness <dbl> 0.00000000, 0.00035600, 0.00000000, 0.000…
## $ liveness <dbl> 0.4520, 0.6490, 0.2840, 0.1820, 0.1370, 0…
## $ valence <dbl> 0.866, 0.780, 0.972, 0.509, 0.770, 0.752,…
## $ tempo <dbl> 137.533, 137.908, 141.393, 103.447, 120.7…
## $ track_id <chr> "6PcTd0nRu0cJP9np0pe6oF", "1MGOjMQUJwrz6h…
## $ analysis_url <chr> "https://api.spotify.com/v1/audio-analysi…
## $ time_signature <int> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,…
## $ artists <list> [<data.frame[1 x 6]>, <data.frame[1 x 6]…
## $ available_markets <list> [<>, <"AD", "AE", "AG", "AL", "AM", "AR"…
## $ disc_number <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ duration_ms <int> 239200, 184973, 158533, 246133, 130800, 1…
## $ explicit <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ track_href <chr> "https://api.spotify.com/v1/tracks/6PcTd0…
## $ is_local <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ track_name <chr> "A Banda Do Ze Pretinho", "Taj Mahal", "A…
## $ track_preview_url <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ track_number <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13…
## $ type <chr> "track", "track", "track", "track", "trac…
## $ track_uri <chr> "spotify:track:6PcTd0nRu0cJP9np0pe6oF", "…
## $ external_urls.spotify <chr> "https://open.spotify.com/track/6PcTd0nRu…
## $ album_name <chr> "A Arte De Jorge Ben Jor", "A Arte De Jor…
## $ key_name <chr> "C#", "F#", "A", "F#", "D#", "A", "E", "C…
## $ mode_name <chr> "minor", "minor", "major", "minor", "mino…
## $ key_mode <chr> "C# minor", "F# minor", "A major", "F# mi…WOW! Muitas variáveis, e muitas delas não me servem de muita coisa, pelo menos para o trabalho que quero realizar aqui, que é uma análise exploratória com foco nas músicas, álbuns, e algumas medidas disponibilizadas pela API. Importante limpar esse banco, removendo essas variáveis que não nos interessam:
jbj <- jbj %>%
select(-ends_with("id"), -album_type, -album_images,
-album_release_date_precision, -analysis_url,
-available_markets, -track_href,
-is_local, -track_preview_url, -type,
-track_uri, -external_urls.spotify,
-key_name, -mode_name, -artists,
-album_release_date, -explicit)Vamos avançar um pouco. Como todos sabem, Jorge Benjor possui muitas músicas dançantes, como “Banda do Zé Pretinho”, “Taj Mahal”, “Mas Que Nada”, “Balança Pema”, dentre outras. Felizmente, o Spotify nos dá acesso a uma variável nesse banco denominada danceability, que nada mais é que um índice que vai de 0 a 1 e mensura o nível de dançabilidade de cada uma das faixas.
Como será que se comportou, ao longo do tempo, o índice de dançabilidade nos álbums de Jorge Benjor?
jbj %>%
group_by(album_name, album_release_year) %>%
summarise(dance_album = mean(danceability)) %>%
ggplot(aes(x = album_release_year, y = dance_album))+
geom_line(color = "#8fd175", size = 1.3)+
geom_point(size = 0.85, color = "#75b8d1")+
geom_smooth(method = "loess", se = F, color = "#75b8d1")+
labs(title = "Dançabilidade nos álbuns de Jorge Benjor",
subtitle = "Considerando todos os álbuns disponíveis no Spotify",
caption = "Fonte: Spotify API",
y = "Média da dançabilidade",
x = "Ano de lançamento do álbum")+
theme_ipsum_tw()+
scale_x_continuous(breaks = seq(1960, 2020, 5),
minor_breaks = NULL)## `summarise()` has grouped output by 'album_name'. You can override using the `.groups` argument.## `geom_smooth()` using formula 'y ~ x'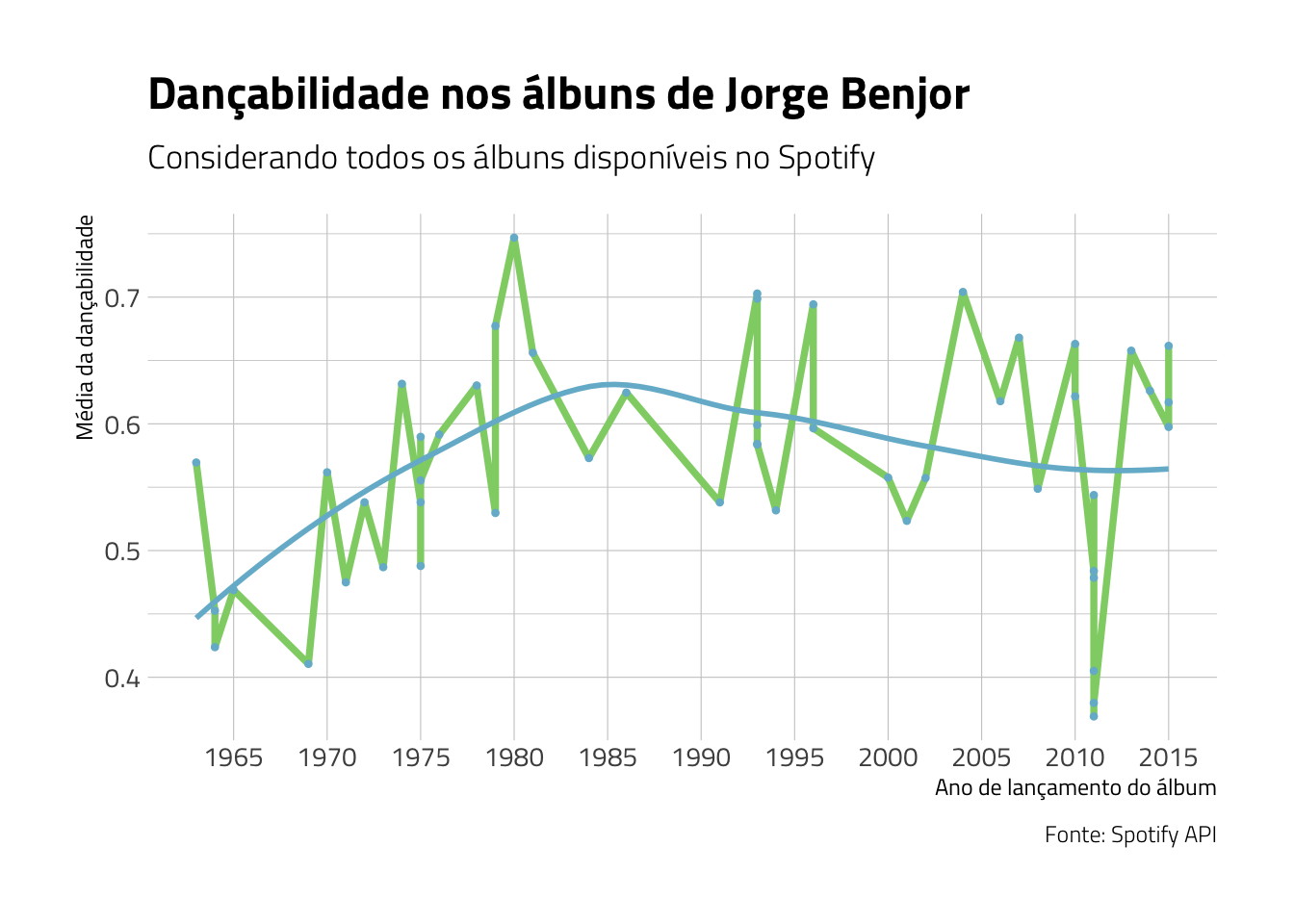
Observamos acima um pequeno problema: em alguns anos, como 1975, 1979, 1993, 1996, 2010, 2011, 2014 e 2015, existe mais de um álbum, o que torna o gráfico um pouco confuso em alguns anos. Podemos perceber os anos em que foi lançado mais de um álbum na tabela a seguir:
jbj %>%
group_by(album_name, album_release_year) %>%
summarise(dance_album = mean(danceability)) %>%
tabyl(album_release_year) %>%
filter(n > 1) %>%
select(-percent) %>%
arrange(-n) %>%
kable(col.names = c("Ano", "Nº de álbuns")) %>%
kable_paper()## `summarise()` has grouped output by 'album_name'. You can override using the `.groups` argument.| Ano | Nº de álbuns |
|---|---|
| 2011 | 6 |
| 1993 | 5 |
| 1975 | 4 |
| 2015 | 3 |
| 1964 | 2 |
| 1979 | 2 |
| 1996 | 2 |
| 2010 | 2 |
Assim, vamos analisar então a distribuição da dançabilidade de Jorge Benjor na sua carreira. Façamos também o seguinte: em 1989, Jorge Ben alterou seu nome artístico para Jorge Benjor. Vamos dividir sua carreira nessas duas fases e analisar, comparando-as, a dançabilidade:
jbj %>%
mutate(nome = ifelse(album_release_year < 1989, "Jorge Ben", "Jorge Benjor")) %>%
group_by(album_name, album_release_year, nome) %>%
summarise(dance_album = mean(danceability)) %>%
ggplot(aes(x = dance_album))+
geom_density(aes(fill = nome),
alpha = 0.6)+
labs(title = "Jorge Ben x Jorge Benjor: o mais dançante",
subtitle = "Em 1989, Jorge Ben se torna Jorge Benjor",
caption = "Fonte: Spotify API",
y = "Densidade",
x = "Média da Dançabilidade por álbum",
fill = "Nome artístico")+
theme_ipsum_tw()+
scale_fill_ipsum()+
theme(legend.position = "bottom")+
scale_x_continuous(breaks = seq(0.3, 0.75, 0.05))## `summarise()` has grouped output by 'album_name', 'album_release_year'. You can override using the `.groups` argument.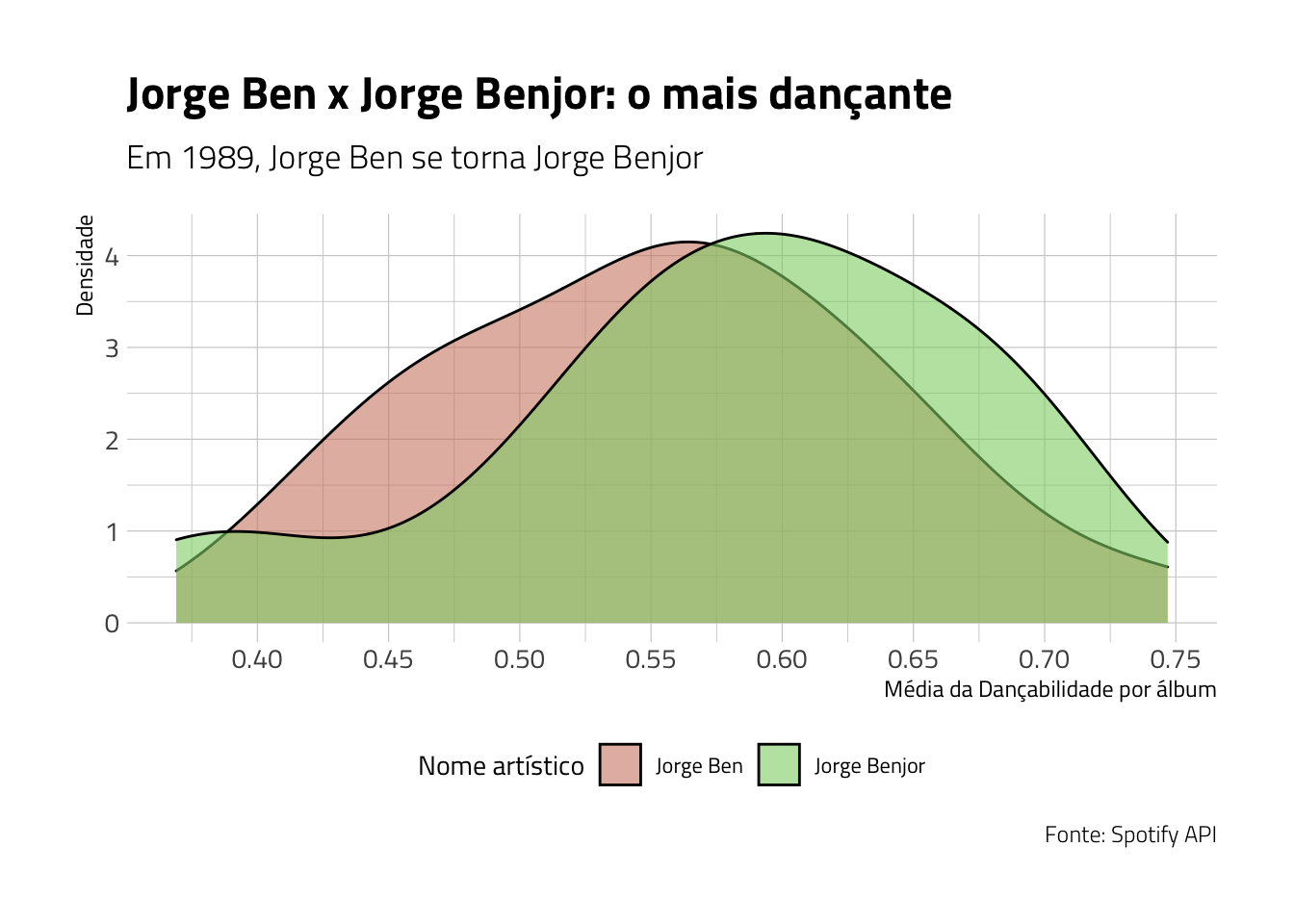
O que se pode perceber no gráfico acima é que, em extensão, a dançabilidade de ambas as fases artísticas de Jorge Ben/Jorge Benjor está localizada não só no mesmo extensão, como as suas médias se aproximam bastante. Logo, a mudança de nome não representou tanto uma mudança no estilo das músicas: todas continuaram bem dançantes. O que podemos perceber é que existem mais músicas de Jorge Ben entre 0.4 e 0.5 de dançabilidade do que de Jorge Benjor. Em contrapartida, Jorge Benjor possui mais músicas que Jorge Ben nos níveis acima de 0.60.
O Spotify, na sua API, nos oferece também uma variável denominada valence, que representa a positividade de uma música, a partir de sua batida, ritmo, tons, etc, sem considerar o teor das letras. Vamos a seguir analisar os 10 álbuns com as maiores valências, que eu denominarei aqui como positividade, e fazer o mesmo exercício que foi feito no gráfico anterior, dividindo entre Jorge Ben e Jorge Benjor:
jbj %>%
mutate(nome = ifelse(album_release_year < 1989, "Jorge Ben", "Jorge Benjor")) %>%
group_by(album_name, album_release_year, nome) %>%
summarise(valence_album = mean(valence)) %>%
head(10) %>%
ggplot(aes(x = reorder(album_name, valence_album),
y = valence_album, color = nome))+
geom_lollipop(horizontal = F, point.size = 2.5)+
coord_flip()+
theme_ipsum_tw()+
scale_color_ipsum()+
theme(legend.position = "bottom")+
labs(x = "Álbum",
y = "Média de positividade do álbum",
title = "Positividade em Jorge Benjor",
subtitle = "Separando os dois Jorges",
color = "Nome artístico",
caption = "Fonte: Spotify API")## `summarise()` has grouped output by 'album_name', 'album_release_year'. You can override using the `.groups` argument.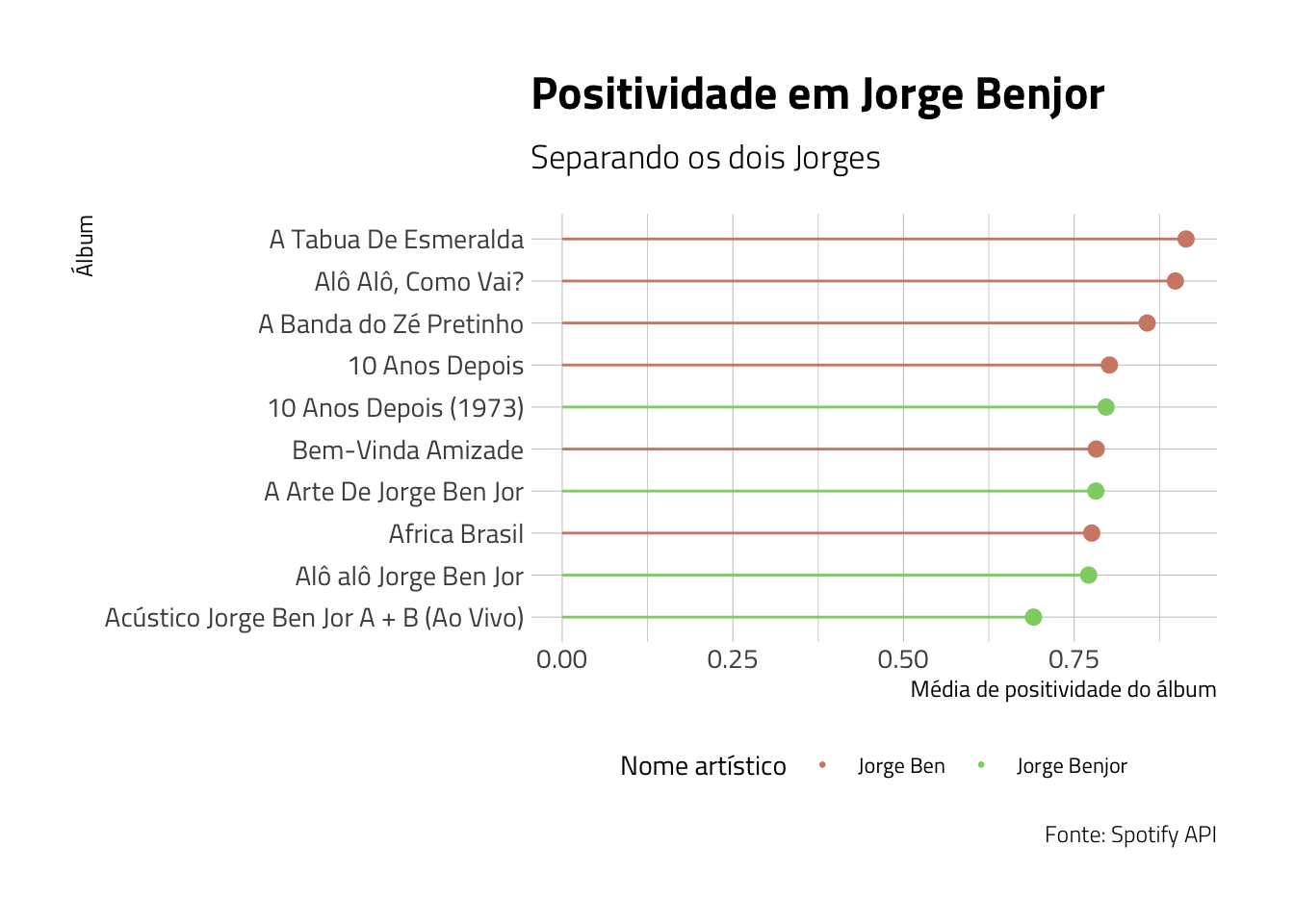
É notável que são poucas as diferenças na positividade entre as duas “fases” do artista. De 10 álbuns com maiores índices de positividade, 5 são do Jorge Ben e 5 são do Jorge Benjor. Talvez, se pudéssemos resumir o artista e sua obra à essas duas variáveis (dançabilidade e positividade), poderíamos contrargumentar qualquer um que fale “prefiro o Jorge Ben ao Jorge Benjor…”.
Uma variável curiosa também cedida pelo Spotify em sua API é a key_mode, ou seja, o tom da música. Será que existe um tom que predomine nas músicas de Jorge Benjor? Vamos descobrir:
jbj %>%
tabyl(key_mode) %>%
ggplot(aes(x = reorder(key_mode, n), y = n))+
geom_col(fill = "#75b8d1", color = "white")+
coord_flip()+
theme_ipsum_tw()+
labs(title = "O tom favorito do Jorge Benjor",
subtitle = "Considerando todas as músicas disponíveis no Spotify",
x = "Tom",
y = "Quantidade de músicas",
caption = "Fonte: Spotify API")+
scale_y_continuous(breaks = seq(0, 80, 10))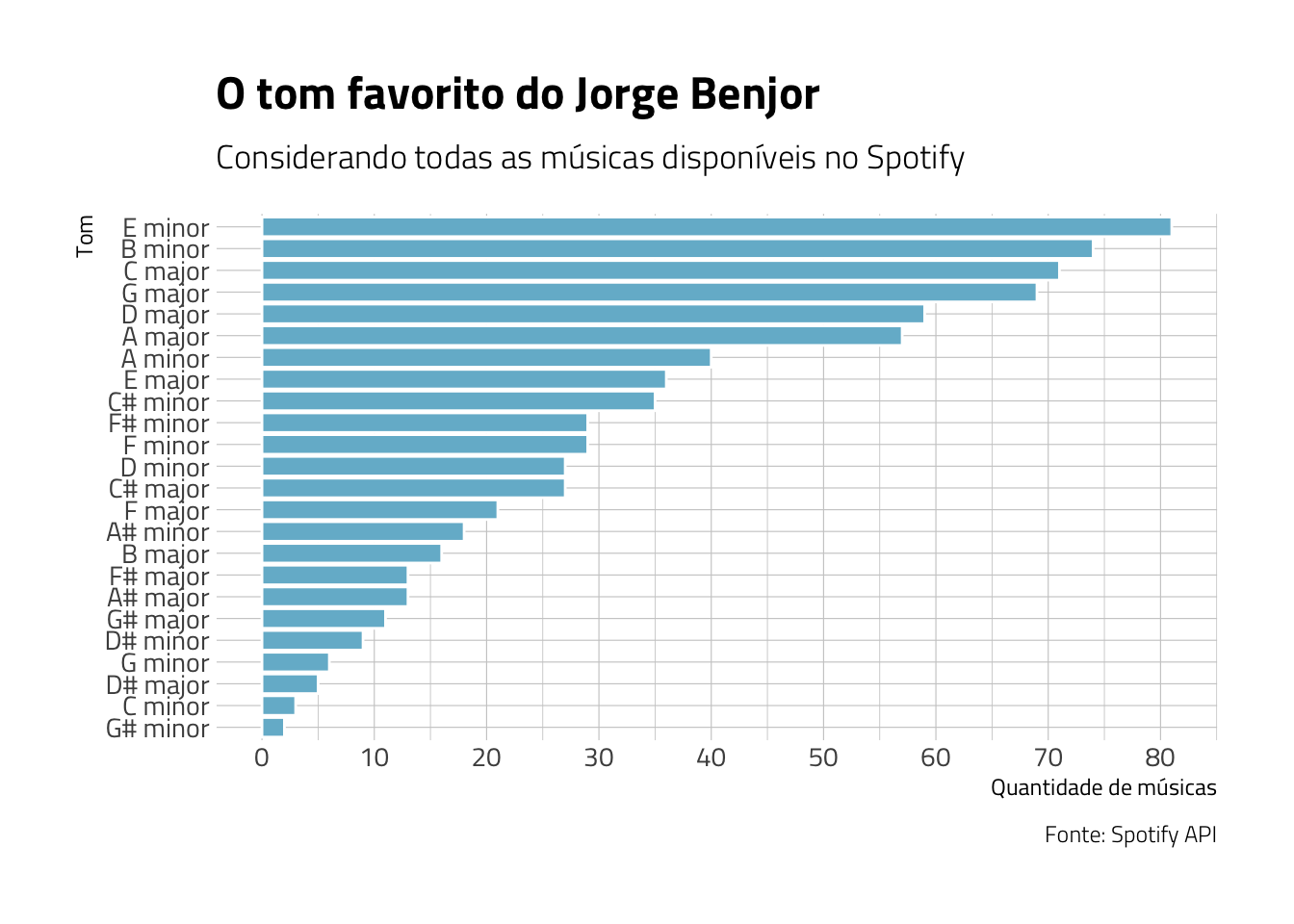
Fica claro que, se fôssemos escolher os 5 tons mais predominantes em toda a produção musical do artista, escolheríamos, na ordem: Mi Menor, Si Menor, Dó Maior, Sol Maior e Ré Maior.
Para finalizar, vamos analisar meu álbum favorito do Jorge: A Tábua de Esmeralda, considerado um álbum alquímico, no sentido literal da palavra. As faixas presentes no álbum são as seguintes:
jbj %>%
filter(album_name == "A Tabua De Esmeralda") %>%
select(track_number, track_name) %>%
kable(col.names = c("Nº da faixa", "Nome da faixa")) %>%
kable_paper()| Nº da faixa | Nome da faixa |
|---|---|
| 1 | Os Alquimistas Estão Chegando Os Alquimistas |
| 2 | O Homem Da Gravata Florida |
| 3 | Errare Humanum Est |
| 4 | Menina Mulher Da Pele Preta |
| 5 | Eu Vou Torcer |
| 6 | Magnólia |
| 7 | Minha Teimosia, Uma Arma Pra Te Conquistar |
| 8 | Zumbi |
| 9 | Brother |
| 10 | O Namorado Da Viúva |
| 11 | Hermes Trismegisto E Sua Celeste Tábua De Esmeralda |
| 12 | Cinco Minutos (5 Minutos) |
Agora, analisando a dançabilidade, a positividade e a energia (outra variável incrível que o Spotify consolida entre seus dados), podemos analisar todo esse álbum:
jbj %>%
filter(album_name == "A Tabua De Esmeralda") %>%
pivot_longer(cols = c(danceability, valence, energy),
names_to = "medida", values_to = "valor") %>%
ggplot(aes(x = track_number, y = valor, color = medida))+
geom_line(size = 1.2)+
geom_point(size = 2)+
theme_ipsum_tw()+
scale_color_ipsum(labels = c("Dançabilidade", "Energia", "Positividade"))+
scale_x_continuous(breaks = seq(1,12,1),
minor_breaks = NULL)+
scale_y_continuous(breaks = seq(0.3, 1, 0.1),
minor_breaks = NULL)+
labs(title = "A Tábua de Esmeralda: análise das músicas",
subtitle = "É verdade sem mentira certo muito e verdadeiro",
x = "Nº da faixa",
y = "",
caption = "Fonte: Spotify API",
color = "")+
theme(legend.position = "bottom")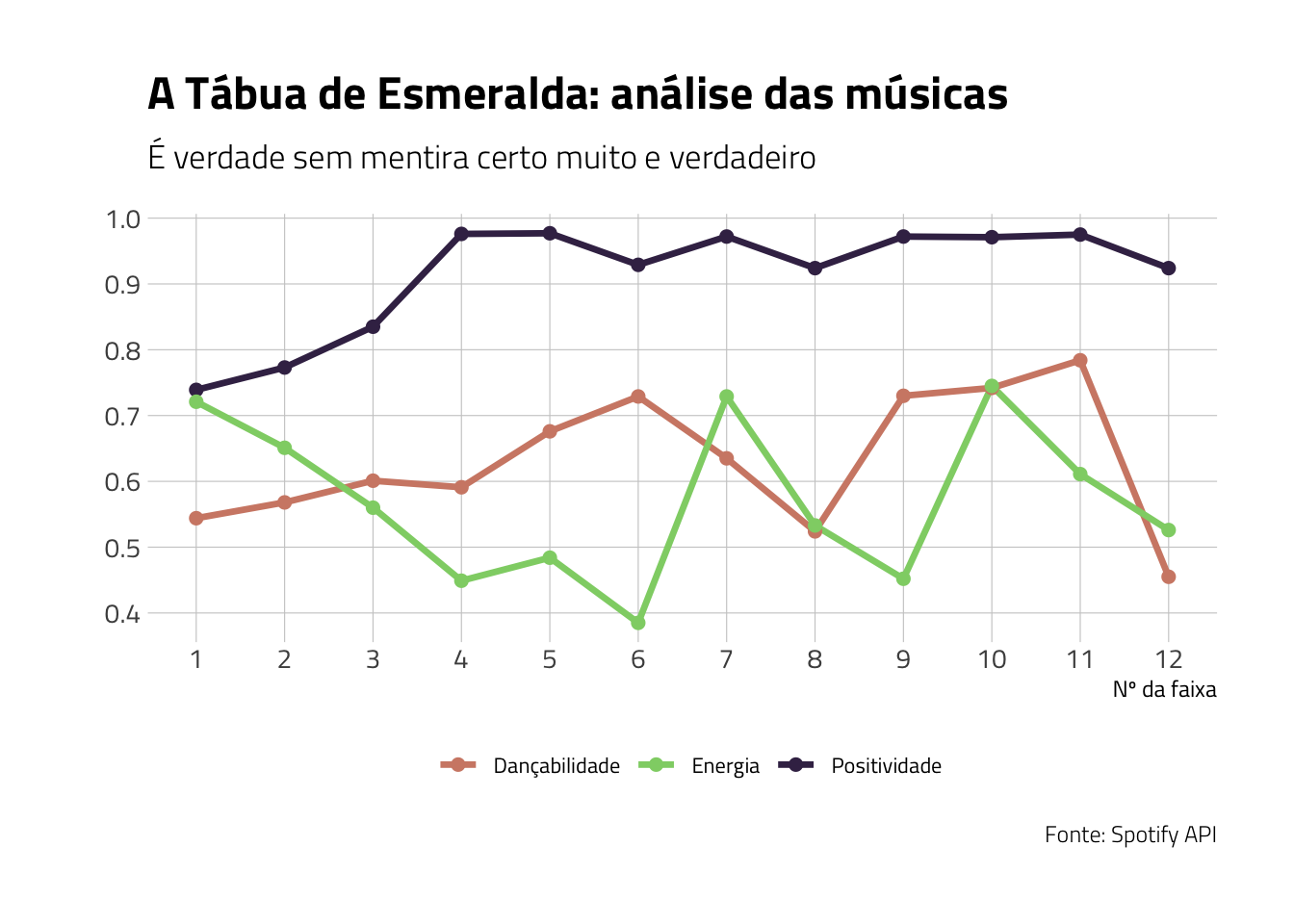
É possível perceber que a positividade do álbum cresce até a faixa 4, “Menina Mulher da Pele Preta”, e a partir daí, mantém-se estabilizada. A dançabilidade possui certa volatilidade: inicia acima de 0.5, cresce timidamente até a faixa 6, “Magnólia”, cai em “Zumbi”, sobe novamente e atinge o ápice em “Hermes Trismegisto e Sua Celeste Tábua de Esmeralda”, uma música que, de fato, é mais dançante que as demais do álbum, e cai completamente na última faixa, denominada “Cinco Minutos”. Mais volátil ainda é a energia, que começa alta, atinge o valor mínimo em “Magnólia”, cresce em “Minha Teimosia, Uma Arma pra Te Conquistar”, cai em “Brother”, eleva-se novamente em “O Namorado da Viúva” e termina baixa em “Cinco Minutos”.
Saindo um pouco desse banco, quais serão as top tracks de Jorge Benjor? Para isso, o SpotifyR oferece a função denominada get_artist_top_tracks(), que nos oferece as 10 músicas mais ouvidas do artista no Spotify, nos dando algumas das mesmas variáveis de antes. Diferente da função utilizada anteriormente, que permitia que escrevêssemos o nome do artista, a get_artist_top_tracks só permite o ID do mesmo. Para encontrar o ID do Jorge Benjor, retornaremos ao banco anterior. Sei que a variávei artist_id possui essa informação, repetida para cada faixa presente no banco. Por isso, criarei um objeto com esse id para utilizar a função.
get_artist_audio_features("jorge benjor") %>%
pull(artist_id) %>%
first() -> jbj_id
jbj_top <- get_artist_top_tracks(jbj_id)
glimpse(jbj_top)## Rows: 10
## Columns: 28
## $ artists <list> [<data.frame[26 x 6]>, <data.frame[1 x 6…
## $ disc_number <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
## $ duration_ms <int> 168948, 179293, 298026, 184093, 177200, 2…
## $ explicit <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ href <chr> "https://api.spotify.com/v1/tracks/60M76S…
## $ id <chr> "60M76S6OMP5vnqZW7D4Nad", "6U03Orwr5Dxt8j…
## $ is_local <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ is_playable <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE,…
## $ name <chr> "Camarão Que Dorme a Onda Leva", "Mas, Qu…
## $ popularity <int> 61, 57, 0, 56, 55, 37, 55, 53, 52, 52
## $ preview_url <chr> "https://p.scdn.co/mp3-preview/bc19682723…
## $ track_number <int> 13, 1, 6, 5, 4, 11, 6, 1, 5, 12
## $ type <chr> "track", "track", "track", "track", "trac…
## $ uri <chr> "spotify:track:60M76S6OMP5vnqZW7D4Nad", "…
## $ album.album_type <chr> "album", "album", "album", "album", "albu…
## $ album.artists <list> [<data.frame[1 x 6]>, <data.frame[1 x 6]>…
## $ album.href <chr> "https://api.spotify.com/v1/albums/3dSIcc…
## $ album.id <chr> "3dSIccF3oBqXQTci6p7HEX", "3xWp6y0HGsHZlX…
## $ album.images <list> [<data.frame[3 x 3]>, <data.frame[3 x 3]…
## $ album.name <chr> "Sambabook Zeca Pagodinho, Vol. 2", "Samb…
## $ album.release_date <chr> "2014-03-20", "1963-01-01", "2021-02-26",…
## $ album.release_date_precision <chr> "day", "day", "day", "day", "day", "day"…
## $ album.total_tracks <int> 13, 12, 29, 12, 12, 14, 11, 12, 11, 12
## $ album.type <chr> "album", "album", "album", "album", "albu…
## $ album.uri <chr> "spotify:album:3dSIccF3oBqXQTci6p7HEX", "…
## $ album.external_urls.spotify <chr> "https://open.spotify.com/album/3dSIccF3o…
## $ external_ids.isrc <chr> "BRUKM1400027", "BRMCA6300083", "BRMCA020…
## $ external_urls.spotify <chr> "https://open.spotify.com/track/60M76S6OM…jbj_top %>%
arrange(-popularity) %>%
select(name) %>%
mutate(index = row_number()) %>%
kable(col.names = c("Nome da faixa", "Posição #")) %>%
kable_paper()| Nome da faixa | Posição # |
|---|---|
| Camarão Que Dorme a Onda Leva | 1 |
| Mas, Que Nada! | 2 |
| Chove Chuva | 3 |
| Menina Mulher Da Pele Preta | 4 |
| Take It Easy My Brother Charles | 5 |
| Os Alquimistas Estão Chegando Os Alquimistas | 6 |
| País Tropical | 7 |
| Por Causa De Você, Menina | 8 |
| Oba, Lá Vem Ela | 9 |
| Menina Mulher Da Pele Preta / O Telefone Tocou Novamente - Ao Vivo | 10 |
Ok, temos as 10 músicas, na ordem de popularidade. Vamos plotar esse gráfico:
jbj_top %>%
ggplot(aes(x = reorder(name, popularity), y = popularity))+
geom_col(fill = "#8fd175", color = "black", size = 0.35)+
theme_ipsum_tw()+
labs(title = "Top Tracks Jorge Benjor",
x = "Nome da faixa",
y = "Popularidade",
caption = "Fonte: Spotify API")+
coord_flip()+
scale_y_continuous(breaks = seq(0, 60, 10))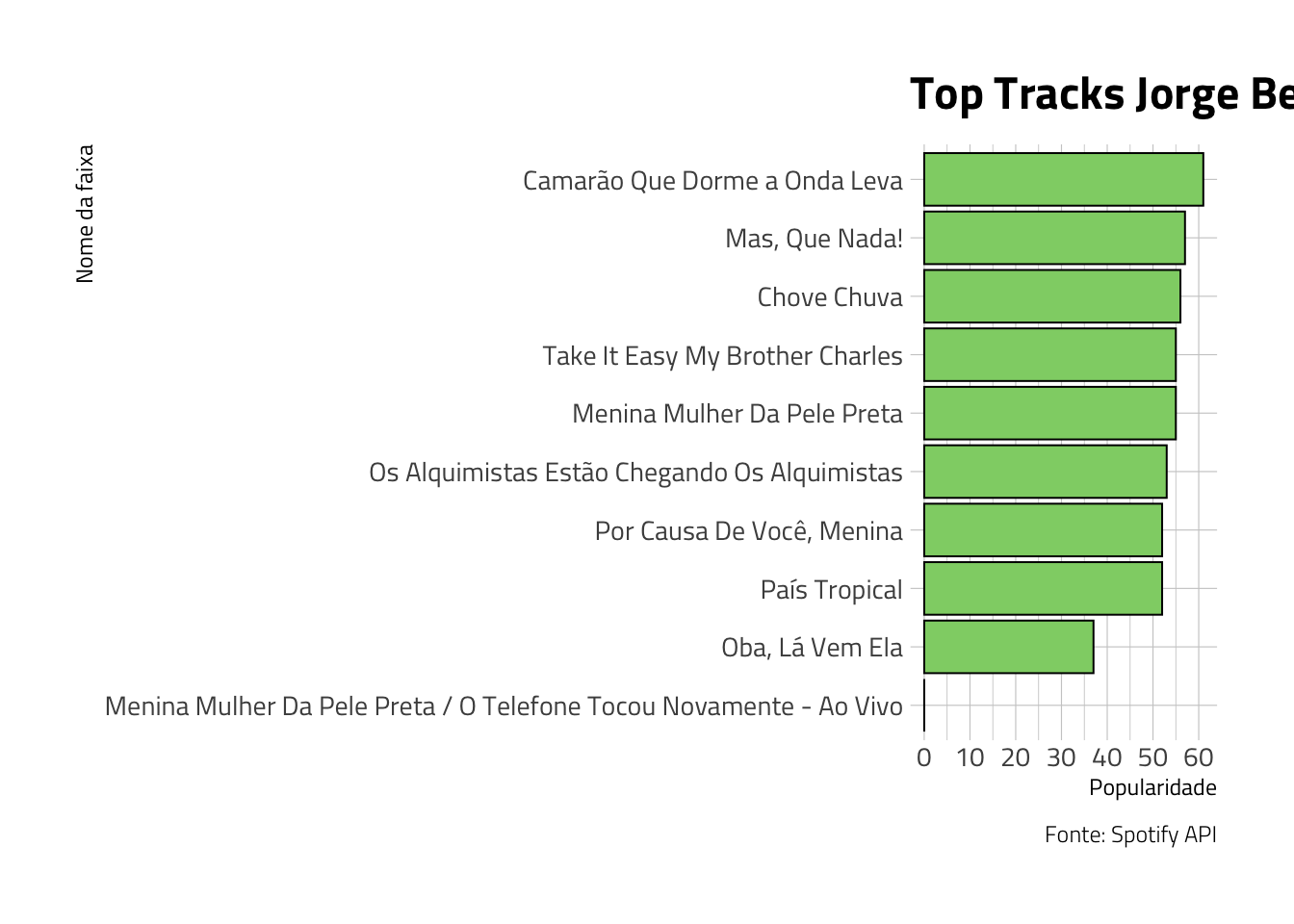
Como percebemos, o sucesso “Mas que nada!”, na voz de Jorge Benjor, é o mais popular dentre os usuários do Spotify! Mas estamos falando do mercado global. E se comparássemos 3 mercados diferentes, como por exemplo, Brasil, Estados Unidos e Japão? Será que os 3 países tem as mesmas músicas no Top 10?
jbj_top_jp <- get_artist_top_tracks(jbj_id, market = "JP") %>%
select(id, name, popularity_jp = popularity)
jbj_top_br <- get_artist_top_tracks(jbj_id, market = "BR") %>%
select(id, name, popularity_br = popularity)
jbj_top_us <- get_artist_top_tracks(jbj_id, market = "US") %>%
select(id, name, popularity_us = popularity)
jbj_top_all <- inner_join(jbj_top, jbj_top_br, by = "name")
jbj_top_all <- inner_join(jbj_top_all, jbj_top_jp, by = "name")
jbj_top_all <- inner_join(jbj_top_all, jbj_top_us, by = "name")Ao observar cada um dos bancos, percebi que existem músicas que são mais tocadas no Japão, como “Por causa de você, menina”, que não está presente nem no Brasil nem nos Japão. Ao mesmo tempo, a versão pout-pourri de “Menina Mulher da Pele Preta / O telefone tocou novamente” só existe no Brasil e no Japão, e não nos EUA. Foi preciso, então, fazer um inner_join() para gerar uma lista que contenha somente as faixas no top 10 de todos os 3 mercados. No caso, restaram 8 músicas. MDessa forma, somente compararemos o que for comparável entre os países.
jbj_top_all %>%
select(name, starts_with("pop")) %>%
kable(col.names = c("Nome da faixa", "Pop. Global", "Pop. BR", "Pop. JP", "Pop. US")) %>%
kable_paper()| Nome da faixa | Pop. Global | Pop. BR | Pop. JP | Pop. US |
|---|---|---|---|---|
| Camarão Que Dorme a Onda Leva | 61 | 61 | 61 | 61 |
| Mas, Que Nada! | 57 | 57 | 57 | 57 |
| Menina Mulher Da Pele Preta / O Telefone Tocou Novamente - Ao Vivo | 0 | 57 | 57 | 0 |
| Chove Chuva | 56 | 56 | 56 | 56 |
| Menina Mulher Da Pele Preta | 55 | 55 | 55 | 55 |
| Oba, Lá Vem Ela | 37 | 55 | 55 | 37 |
| Take It Easy My Brother Charles | 55 | 55 | 55 | 55 |
| Os Alquimistas Estão Chegando Os Alquimistas | 53 | 53 | 53 | 53 |
| País Tropical | 52 | 52 | 52 | 52 |
| Por Causa De Você, Menina | 52 | 52 | 52 | 52 |
jbj_top_all[6,9] <- "Os Alquimistas Estão Chegando"
jbj_top_all %>%
pivot_longer(cols = c(starts_with("Pop")), values_to = "Popularidade", names_to = "Mercado") %>%
select(Faixa = name, Mercado, Popularidade) %>%
mutate(Mercado = case_when(Mercado == "popularity" ~ "Global",
Mercado == "popularity_br" ~ "Brasil",
Mercado == "popularity_us" ~ "EUA",
Mercado == "popularity_jp" ~ "Japão")) -> jbj_top_graphs
jbj_top_graphs %>%
ggplot(aes(x = Faixa, y = Popularidade, fill = Mercado))+
geom_col(aes(group = factor(Faixa)), position = "dodge2")+
theme_ipsum_tw()+
coord_flip()+
scale_fill_ipsum()+
theme(legend.position = "bottom")+
scale_y_continuous(breaks = seq(0, 70, 10))+
labs(title = "Jorge Benjor pelo Mundo",
subtitle = "Comparando Mundo, Brasil, EUA e Japão",
caption = "Fonte: SpotifyR")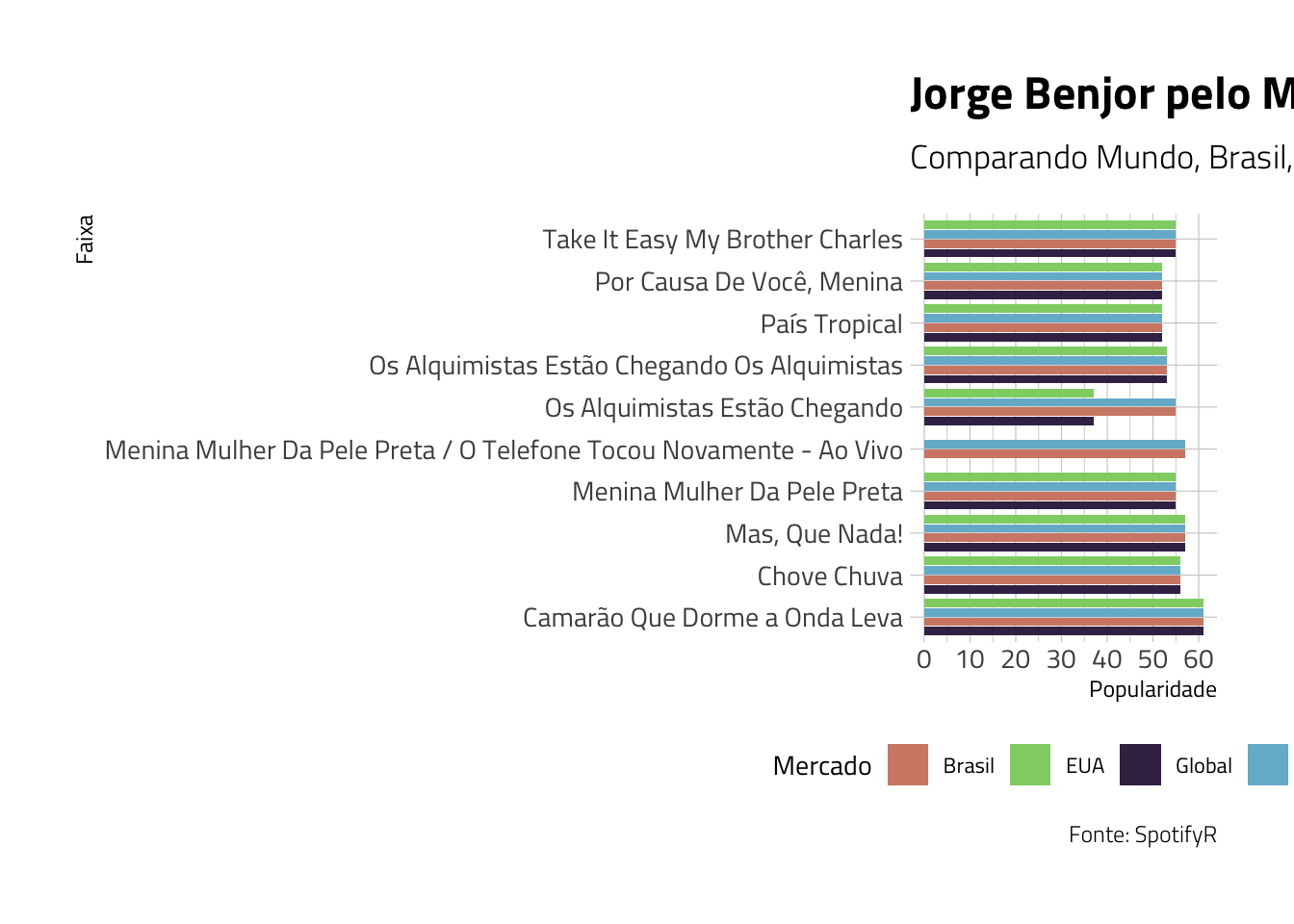 O que podemos perceber é que, dentre as 8 músicas que são comuns aos 4 top 10 (o global, o brasileiro, o americano e o japonês), em todas as canções a popularidade é a mesma, menos na música “Oba, Lá Vem Ela”, que é menos gostada nos EUA e no Mundo, mas é muito ouvida no Brasil e no Japão.
O que podemos perceber é que, dentre as 8 músicas que são comuns aos 4 top 10 (o global, o brasileiro, o americano e o japonês), em todas as canções a popularidade é a mesma, menos na música “Oba, Lá Vem Ela”, que é menos gostada nos EUA e no Mundo, mas é muito ouvida no Brasil e no Japão.
Bom, por hoje é só! É preciso agradecer principalmente ao criador do SpotifyR, cujo link pode ser encontrando no início do post, e também à Mia Smith, com um elucidador artigo que explora a API, e Simran Vatsa, que serviu de inspiração com seu excelente trabalho sobre os álbuns da Taylor Swift.
Qualquer dúvida, correção ou sugestão pode ser encaminhada para matheus.pestana@iesp.uerj.br
Mateus Cavalcanti Pestana
Doutorando e Mestre em Ciência Política
Interessado em ciência de dados, ciência política, política russa, impressão 3D, redes neurais e aprendizado de máquina.